

A defective software update from cybersecurity firm CrowdStrike for its Microsoft Windows hosts left hospitals, banks, airlines, and other businesses scrambling during a global mass IT outage weeks ago.

CrowdStrike founder and CEO George Kurtz has since apologised to their customers and partners in a letter he penned in the aftermath of the outage, saying that nothing is more important to him than their “trust and confidence.”
The aftermath
In the aftermath of the outage, verified business and technology professionals participating in Gartner Peer Community polls and discussions revealed that the majority said the outage had some impact on their organisations, with 47% saying it had either a severe impact (14%) or a significant impact (33%) on their operations. In comparison, 20% said there was no impact.
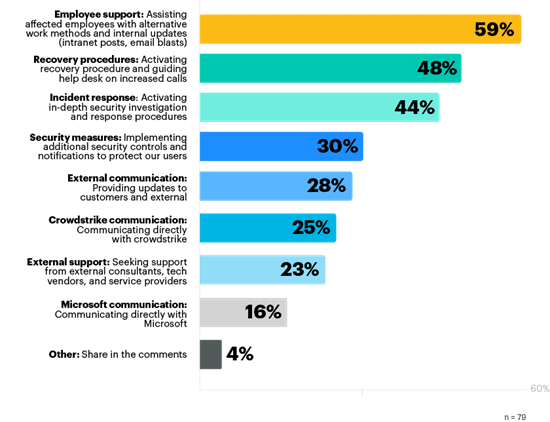
To mitigate risks and manage the impact of the outage, organisations focused on employee support by assisting affected employees with alternative work arrangements and internal updates (59%). Almost half (48%) said their organisations focused on activating recovery procedures and guiding the help desk on increased calls, while 44% of respondents said their organisations focused on incident response by activating in-depth security investigations and response procedures.
Other actions organisations took are implementing additional security controls (30%), providing updates to customers and external stakeholders (28%), communicating directly with CrowdStrike (25%), seeking support from external consultants, vendors (23%), and service providers, and talking directly with Microsoft (16%).
Lessons from the global IT outage
While unable to confirm if this was the largest IT outage in history Nathan Wenzler, chief security strategist at Tenable, says the incident has left its mark on the global tech and business landscape, with an undeniable impact on an estimated 8.5 million Windows devices.
"An outage of this scale brings several lessons to the fore, and as we reflect a week later, we can distil some critical learnings from this event," declared Wenzler
Commenting on the news, Vishal Ghariwala, chief technology officer (CTO) for SUSE Asia Pacific, says other companies should also prepare for such incidents.
“What happened with Microsoft and CrowdStrike was a situation nobody wants to find themselves in. The incident showed how a seemingly simple IT update can paralyse global IT systems and our day-to-day lives. I don’t think this is about CrowdStrike or Windows. This can happen with any software. More importantly, it stresses the importance of incorporating digital resilience so that mission-critical IT services can withstand serious disruptions,” Ghariwala said.
Reflecting on the lessons learned from the incident, the SUSE executive reminds organisations of some measures they could take to prevent or minimise disruptions caused by IT outages.

“One approach is to reduce software concentration risks by adopting diverse IT stacks, especially for critical services. It may seem counterintuitive, but moving away from monolithic IT environments allows organisations to quickly switch mission-critical operations while they fix the issue at hand."Vishal Ghariwala
He also reminds organisations to consider adopting a dual operating system (OS) strategy so they can easily switch to the other when one is affected.
“This may not always be a cheap and easy architectural, technological, or business decision - especially if companies are trapped in a rigid IT ecosystem that inhibits agility and interoperability. However, in my honest opinion, this is something that every organisation should proactively consider so that their essential IT services can be preserved in the face of major disruptions.” Ghariwala said.
For Forrester VP principal analyst Andras Cser, the solution is attaching a physical keyboard to each affected system, booting into Safe Mode, removing the compromised CrowdStrike update, and rebooting.

"Remediating this issue requires significant effort. Prior track records of similar incidents have shown that vendors’ operations, product testing, and communications strategies only get better after such incidents occur.” Andras Cser
The way forward
Forrester recommends that tech and security leaders empower authorised system administrators to fix problems quickly, communicate internally and externally the impacts, status, and progress of remediation efforts, pay attention to the vendor’s communication strategies, follow official advice, and look after their people.
Once the immediate issue is fixed, Forrester recommends implementing infrastructure automation, refreshing and rehearsing their IT outage response plan, and getting unified, written warranties from security vendors on their quality assurance processes and threat detection effectiveness.
In the longer term, Forrester reminds organisations to reevaluate third-party risk strategy and approach and use the contract as a risk mitigation tool.
Immediate, midterm, and long term
Based on Gartner’s analysis, organisations should organise action plans based on immediate, midterm, and long-term programs.
In the short term, Gartner recommends organisations avoid overreacting by immediately mandating the decommission, disablement, or replacement of affected software.
In terms of midterm actions, organisations could assess the impact of an IT outage on secondary systems, seek exposed vulnerabilities, and ensure visibility into systemwide updates and releases.
It is also wise to review anomalies or unusual trends to minimise the risks of undetected opportunistic attacks, participate in the business impact analysis, communicate with senior leadership on the current status of PCs, check agent automatic update settings, and ensure they are consistent with existing organisational change control policy, and manage burnout/fatigue in your team to minimise the risk of error.
In the long term, it is crucial to mitigate or reduce the risk of the same level of business impact or exposure by reviewing the prevention, response, and support procedures for large-scale outages, checking and updating downtime procedures for critical operations, and revising crisis communication plans, incident response processes and business continuity management/IT disaster recovery plans, and ensuring the competencies of critical employees with response and recovery responsibilities. It is also essential to assess the operational impacts before deploying a security agent.
Significant discussions
The CrowdStrike-Microsoft outage will be a springboard for further significant discussions and questions on risk mitigation, vigilance, testing, and cybersecurity.

“Many organisations will be asking the question about whether or not it will be worth allocating dedicated resources to ensure these sorts of matters are caught in the future by more stringent testing and QA processes, or if they take the risk that another outage like this won’t happen for several more years and the cost of the impact at that time will be less than the cost of the testing process. Each organisation will need to determine the best course of action based on their respective needs and risk tolerance,” Tenable’s Wenzler said.
As organisations globally remain at risk, the lessons from the global IT outage can serve as a wake-up call for them to proactively implement short-, midterm, and long-term measures to strengthen their cybersecurity posture and minimize disruptions caused by large-scale IT outages.
